|
Monitoraggio in continuo dell'erosione costieraLa misurazione della linea di riva da videoLa linea di riva rappresenta il confine istantaneo tra la spiaggia e il mare. La sua posizione varia nel tempo sotto l'effetto delle maree, del moto ondoso e dei processi di erosione costiera o deposizionali di lungo periodo. Monitorare sistematicamente questa posizione permette di rilevare tendenze di arretramento o avanzamento della spiaggia, di valutare l'impatto delle mareggiate e degli eventi meteo-marini estremi sull'evoluzione del litorale, e di supportare la gestione integrata delle coste. Il sistema MOVICO (MOnitoraggio VIdeo COstiero) acquisisce continuamente immagini dalle stazioni di videomonitoraggio RVMC distribuite lungo le coste italiane. A partire da queste immagini, una procedura automatica estrae la posizione della linea di riva con cadenza oraria, produce serie temporali e converte le misure in coordinate geografiche reali, rendendo i dati immediatamente confrontabili con misure di campo e integrabili in sistemi GIS. Schema della procedura di estrazioneIl processo si articola in quattro fasi: una fase preparatoria di costruzione del modello (eseguita una tantum) e tre fasi operative eseguite in sequenza su ogni immagine disponibile.
0. Costruzione del dataset e addestramento — selezione e annotazione
manuale di immagini storiche stratificate per stato del mare; addestramento del modello di
segmentazione su GPU. Fase 0 — Costruzione del dataset e addestramento del modelloIl concettoPrima di poter analizzare automaticamente le immagini, il sistema deve essere “addestrato”: un insieme di immagini viene selezionato e annotato manualmente da esperti, che tracciano con precisione il confine tra acqua e sabbia. Queste immagini costituiscono il dataset di riferimento da cui il modello impara a riconoscere la linea di riva in modo autonomo. Per garantire che il modello funzioni bene in tutte le condizioni meteo-marine, le immagini sono state selezionate in modo equilibrato: una quota simile proviene da giornate di mare calmo, mosso, molto mosso e agitato. Questa strategia — detta campionamento stratificato — evita che il modello impari a riconoscere la riva solo nelle condizioni più frequenti, risultando poi impreciso durante le mareggiate. Approfondimento tecnico
Le immagini sono state selezionate dall'archivio storico MOVICO tramite lo script
Le annotazioni sono state prodotte con il tool CVAT (Computer Vision Annotation Tool), tracciando maschere binarie acqua/non-acqua in formato polygon e RLE su 543 immagini provenienti da 7 stazioni della rete RVMC: TorreCerrano01, acciaroli01, battipaglia01, fogliano01, kufra, senigallia, torresole01. Il dataset è stato suddiviso in training e validation con split stratificato per stazione (80/20, seed=42), garantendo che ogni stazione sia rappresentata in entrambi i set:
Le 10 immagini non utilizzate erano annotate in CVAT ma il corrispondente file immagine non era disponibile su disco al momento dell'addestramento. Split effettivo: 429 immagini training / 104 immagini validation. Fase 1 — Segmentazione semantica con SegFormerIl concettoLa camera acquisisce ogni ora un'immagine timex (media temporale di 15 minuti di video), che attenua il moto ondoso e rende visibile in modo stabile la zona di bagnasciuga. Un algoritmo di intelligenza artificiale analizza automaticamente questa immagine e identifica la zona occupata dall'acqua, distinguendola dalla sabbia asciutta e da altri elementi della scena (strutture, vegetazione, cielo). Il risultato è una maschera binaria: ogni punto dell'immagine risulta classificato come acqua o non-acqua. Il confine tra le due aree corrisponde alla linea di riva.
Fig. 1 — Immagine timex con la linea di riva estratta automaticamente sovrapposta (linea rossa). La timex e una media di 10 minuti di acquisizione video che attenua il moto ondoso. Approfondimento tecnicoIl modello utilizzato è SegFormer-B1, un'architettura transformer per la segmentazione semantica di immagini, eseguita tramite runtime ONNX su CPU per massima portabilita e velocita di inferenza. Il modello è stato addestrato su un dataset di 533 immagini annotate manualmente provenienti da 7 stazioni della rete RVMC, con maschere binarie acqua/non-acqua prodotte con il software di annotazione CVAT. Il preprocessing replica fedelmente le condizioni di training: ridimensionamento a 512×512 pixel, normalizzazione ImageNet (mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), riconversione alla risoluzione originale con interpolazione nearest-neighbor per la maschera. Metriche sul set di validazione (104 immagini, 7 stazioni):
Il mIoU sul set di validazione (0.9743) risulta leggermente superiore a quello di training (0.9737), indicando assenza di overfitting ed eccellente capacita di generalizzazione. L'errore mediano di confine di 0.2 pixel e compatibile con la precisione delle annotazioni manuali, a indicare che il modello ha appreso pattern di classificazione coerenti con gli annotatori umani. Fase 2 — Estrazione della posizione lungo transettiIl concettoUna volta ottenuta la maschera acqua/non-acqua, il sistema individua automaticamente il contorno della zona bagnata e misura dove la linea di riva interseca dei segmenti predefiniti — detti transetti — che partono dalla spiaggia asciutta e puntano verso il mare. La posizione viene espressa come distanza in pixel dal punto iniziale del transetto (lato terra), e aggiornata ogni ora per costruire la serie temporale di posizione della riva. Ogni camera puo avere fino a 10 transetti configurati indipendentemente, permettendo di monitorare diversi settori della spiaggia inquadrata. Approfondimento tecnico
Il contorno della maschera binaria viene estratto con
I transetti sono definiti per ogni camera in file di configurazione YAML,
con convenzione P1 = lato terra, P2 = lato mare. L'intersezione tra il contorno e ciascun
transetto viene campionata con 1000 punti equidistanti. Il risultato viene archiviato in
formato CSV con colonne Il success rate operativo e circa 85% (17 camere su 20 attive). I principali motivi di skip sono: file timex assente (~10%) e fallimento dell'algoritmo gomito in condizioni meteo-marine estreme (~5%). Fase 3 — Georeferenziazione in coordinate UTMIl concettoLe posizioni in pixel sono utili per il monitoraggio relativo (la spiaggia si e allargata o ristretta?), ma per confrontare i dati con misurazioni di campo, rilievi LiDAR o immagini satellitari occorre esprimere la posizione in coordinate geografiche reali. Questo è l'obiettivo della fase di georeferenziazione: ogni punto della linea di riva viene convertito in coordinate metriche nel sistema di riferimento UTM, direttamente integrabili in GIS. La conversione si basa sulla geometria della camera, nota grazie a una procedura di calibrazione che utilizza punti di controllo a terra (GCP): punti fisici ben identificabili nell'immagine di cui si conoscono le coordinate GPS precise.
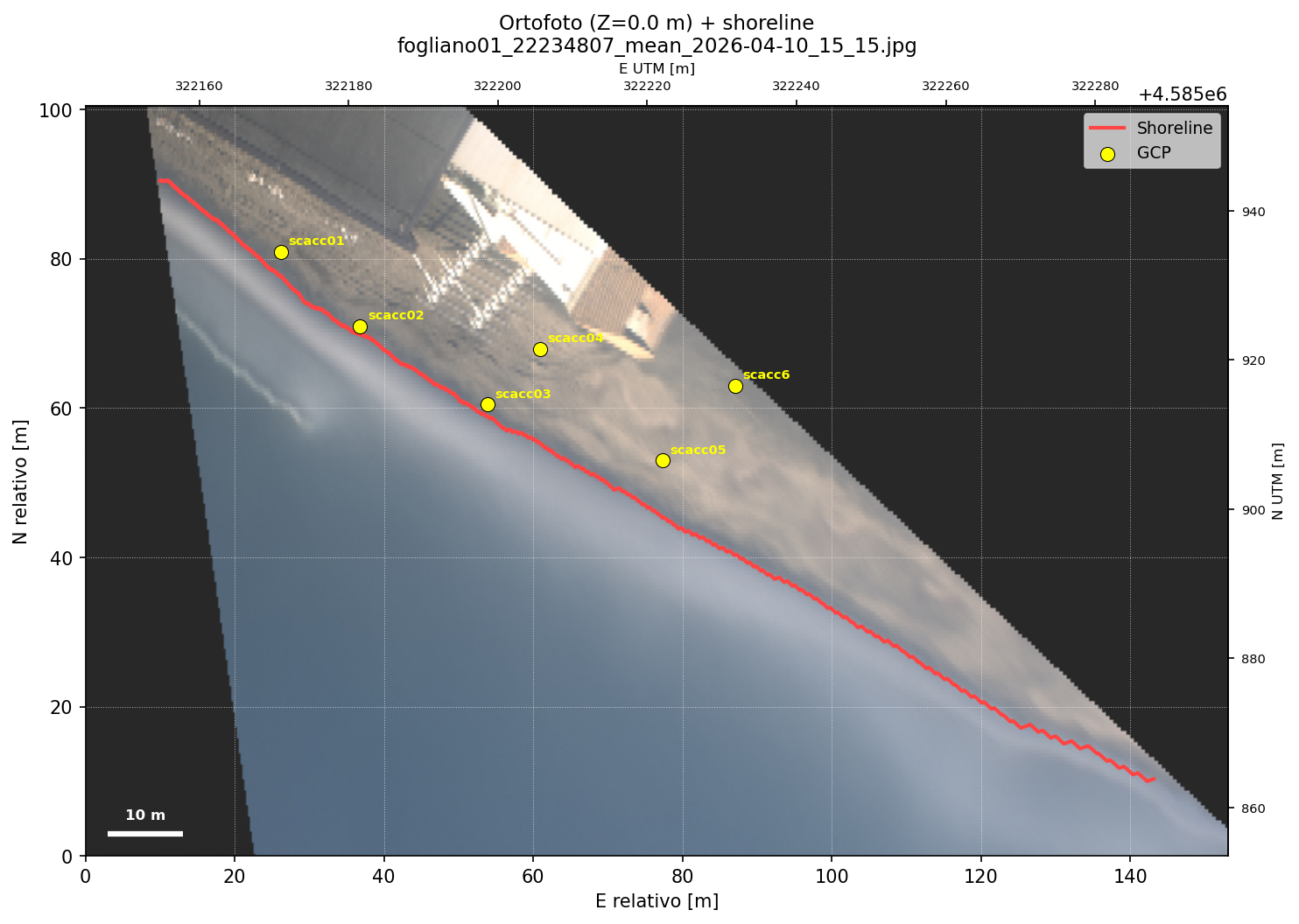
Fig. 2 — Linea di riva georeferenziata rappresentata in coordinate UTM (pianta). I punti di controllo a terra (GCP) usati per la calibrazione sono indicati. Approfondimento tecnico
Il metodo è la back-projection con vincolo di quota (DLT).
Data la posa della camera — matrice di rotazione R e vettore di traslazione t,
ricavati con
s · [u, v, 1]T = K · (R · [X, Y, Z]T + t)
La funzione La distanza metrica dal punto P1 del transetto viene calcolata come proiezione lungo l'asse del transetto (non distanza euclidea diretta), piu robusta in presenza di piccoli scarti laterali. Le coordinate UTM di P1 e P2 sono calcolate una sola volta per transetto e messe in cache. La selezione dei GCP ottimali avviene automaticamente: tra tutte le combinazioni di 6 punti estratti dal set disponibile, il sistema sceglie la combinazione che minimizza l'errore di riproiezione e la salva per i run successivi. L'errore di riproiezione tipico e inferiore a 1 pixel. Output prodotti per ogni immagine:
Sistema operativo e aggiornamento datiLa procedura di analisi è in operativo sul server di elaborazione ISPRA (nominato ecap2). Un processo automatico (cron job) si attiva ogni ora, scarica l'ultima immagine timex disponibile da ciascuna delle ~20 camere attive, esegue l'intera sequenza segmentazione → estrazione → georeferenziazione e archivia i risultati sul server del portale RVMC (nominato ecap1). Il tempo di elaborazione per camera e di circa 1-2 secondi (inferenza ONNX + estrazione), rendendo il sistema idoneo all'aggiornamento orario su hardware standard senza GPU dedicata. I dati di posizione della linea di riva sono consultabili nelle pagine delle singole stazioni e nella sezione Posizione della linea di riva.
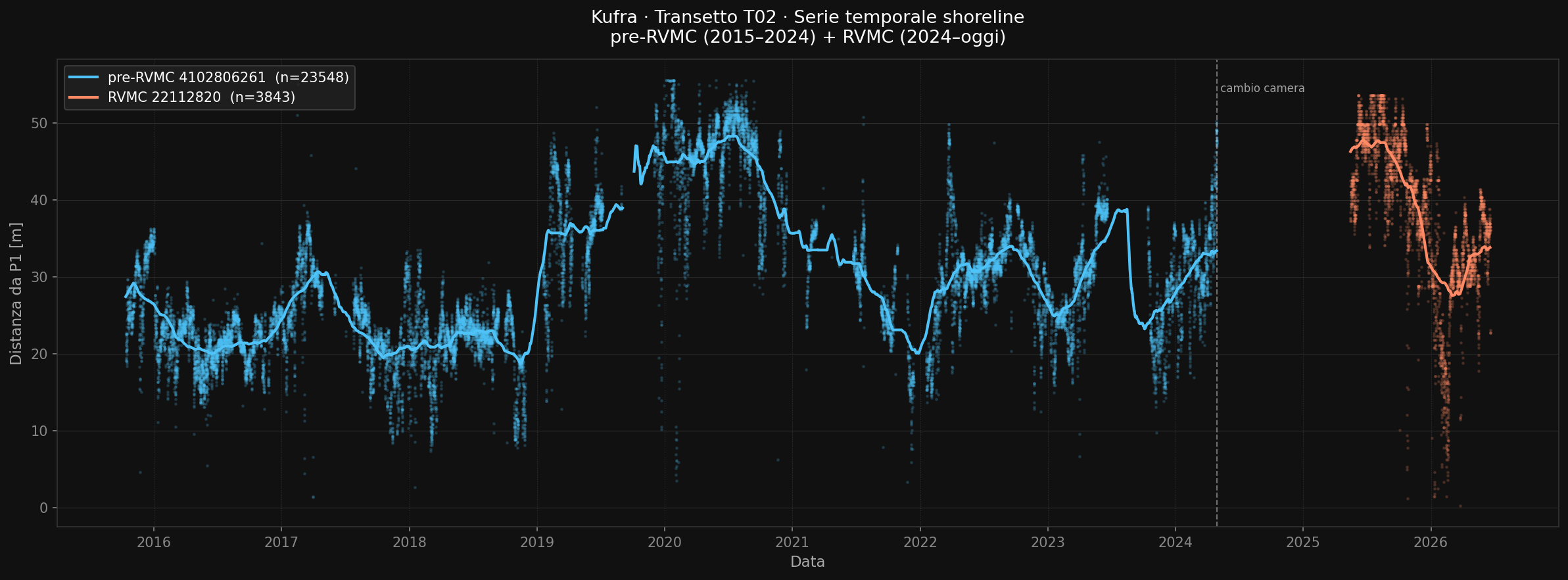
Fig. 3 — Serie temporale del posizionamento della linea di riva estratta dalla stazione di Kufra, risultante dall'elaborazione di 27400 immagini. Riferimenti metodologici principali:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||